Technical Overview
Background As companies have mostly gone remote (or hybrid) post-COVID and are increasingly getting dispersed geographically, there is a growing need for productivity tools that put Asynchronous messaging at the front and centre of their feature offering.
In the domain of Software Quality Assurance, it is a generally accepted fact that speed of fixing defects largely depends on the quality of Software Defect (Bug) Reports. Oftentimes, screenshots and written explanations are not sufficient, and more context information is necessary in terms of how a defect was encountered in the user journey. Besides being cumbersome to write, the written reports might miss out key points or contextual data necessary for either reproducing or fixing a defect, which may mean missed working days in case of distributed teams.
In this document, an asynchronous messaging-based productivity tool that deals with Software Quality Assurance in remote teams has been presented. This Tool has a Browser Extension (for major browsers: Chrome, Firefox, Edge), for collecting the following input data continuously from the point in time when it is indicated to start to the point when it is indicated to stop:
- Screen Recording of User Actions
- Audio of the Narrative of the Person reporting the defect
- Console & Network Logs (using Browser Dev Tools Protocol APIs)
- Environment data (like Browser Version, OS, Memory, etc.) collected only once
Fig. 1 below is a diagram of the Browser Extension and the
multiple communication channels to transport different content types to the Server.
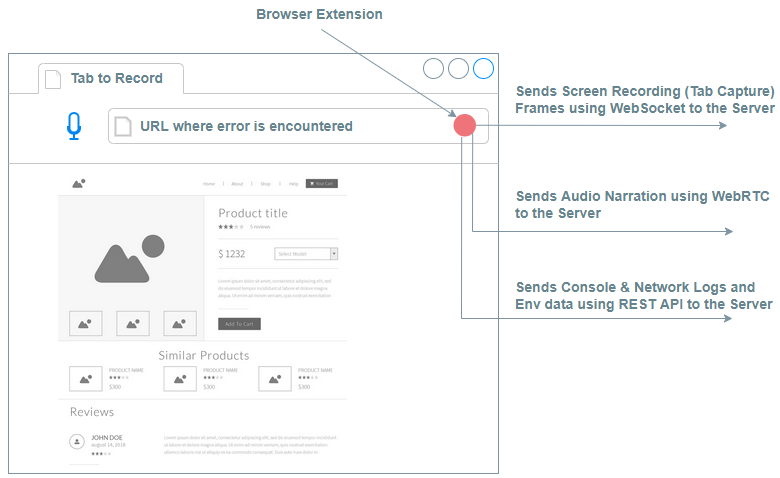
After collecting all the data from these different channels, the tool would generate a Bug Report by merging the Audio Narrative, Screen Recording of User Actions, Console and Network Logs, and User’s Environment data.
Problems The domain of Software Quality Assurance has a few aspects – Bug Reporting, Bug Tracking, and Resolution (Fixing). This Browser Extension deals with the Bug Reporting aspect, and it is the activity that a Person performs once they have encountered a defect or bug and following issues could arise in such a report:
- Encountering a software defect (or an issue) could lead to the Reporter of bug getting distressed or emotionally charged, and they might use abusive language or profanities in their Audio Narrative while describing their issue.
- There could be Team Members who are either hard-of-hearing or are not able to understand the words spoken in the audio.
- The Screen Recording might record sensitive information like a Bank Account Number, Bank Card details, or even Passwords if their visibility toggle is on.
- It could be difficult to find or locate the Video files created in the process.
Solutions In order to alleviate these issues an AI Pipeline must be built so that it can help the Bug Reporter generate a video that would be free of the issues raised above.
- The Audio data that comes in need to be scanned for Profanity and be replaced with a Bleep Censor sound.
- The Audio needs to be Transcribed and Closed Captions (subtitles) must be added to complement the speech.
- The Video Frames must be scanned to check for private/sensitive information and any such input data must be blurred out.
- A Friendly URL (for SEO purposes) along with an editable Report Title needs to be generated using the Transcribed text of the Audio file as the Input. This Transcribed text can also be used for searching a Video.
An AI Pipeline is going to perform all the steps mentioned in the solution from points 1 - 4 and merge the Profanity-free Audio and Redaction-free Screen Recording Video Frames into a Video file that also has Closed Captions. As an aside, this AI Pipeline will also generate a Report Title and Friendly URL for the Report.
In an Enterprise productivity tool, the concerns regarding Data Privacy, Profanity censorship, Inclusiveness and Accessibility, and Searchability are of paramount importance. The AI Pipeline can successfully provide: Data Privacy through Redacting sensitive content; Profanity censorship by speech recognition, profanity detection, and inserting bleep sound; Inclusiveness and
Accessibility by generating Closed Captions with limited hearing and language understanding; Searchability through Friendly URL generation from the transcribed text of the audio narrative.
A Mock up diagram of the Bug Report using the outputs of the AI Pipelines is
shown below in Fig. 2. The text in blue are all the features that are powered by
the AI Pipelines.
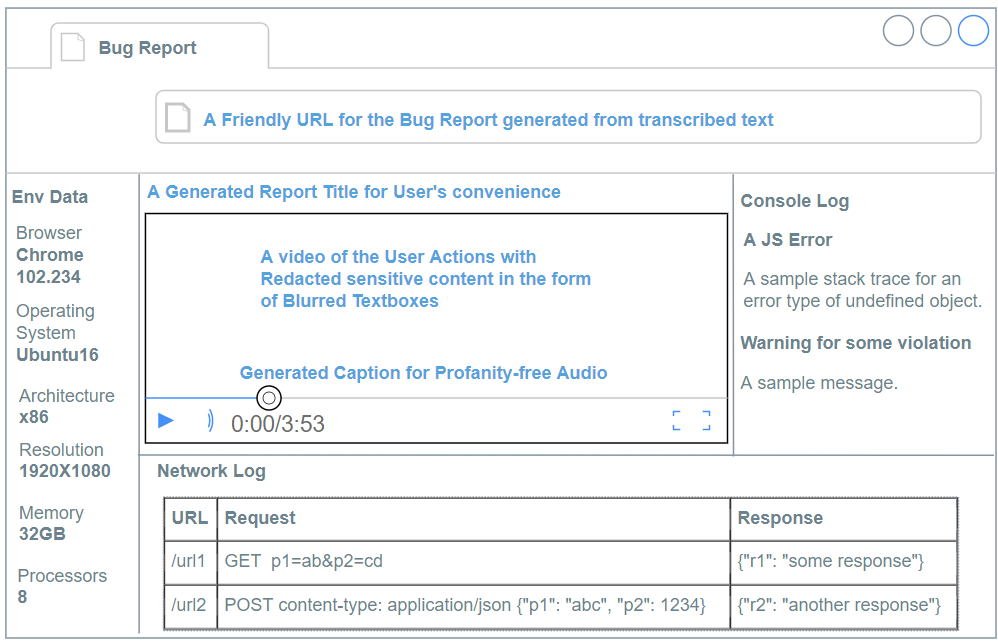
The tangible outcomes of such an AI Pipeline are visible in the above Mock up and can be directly mapped to creating a responsible product for an Enterprise.
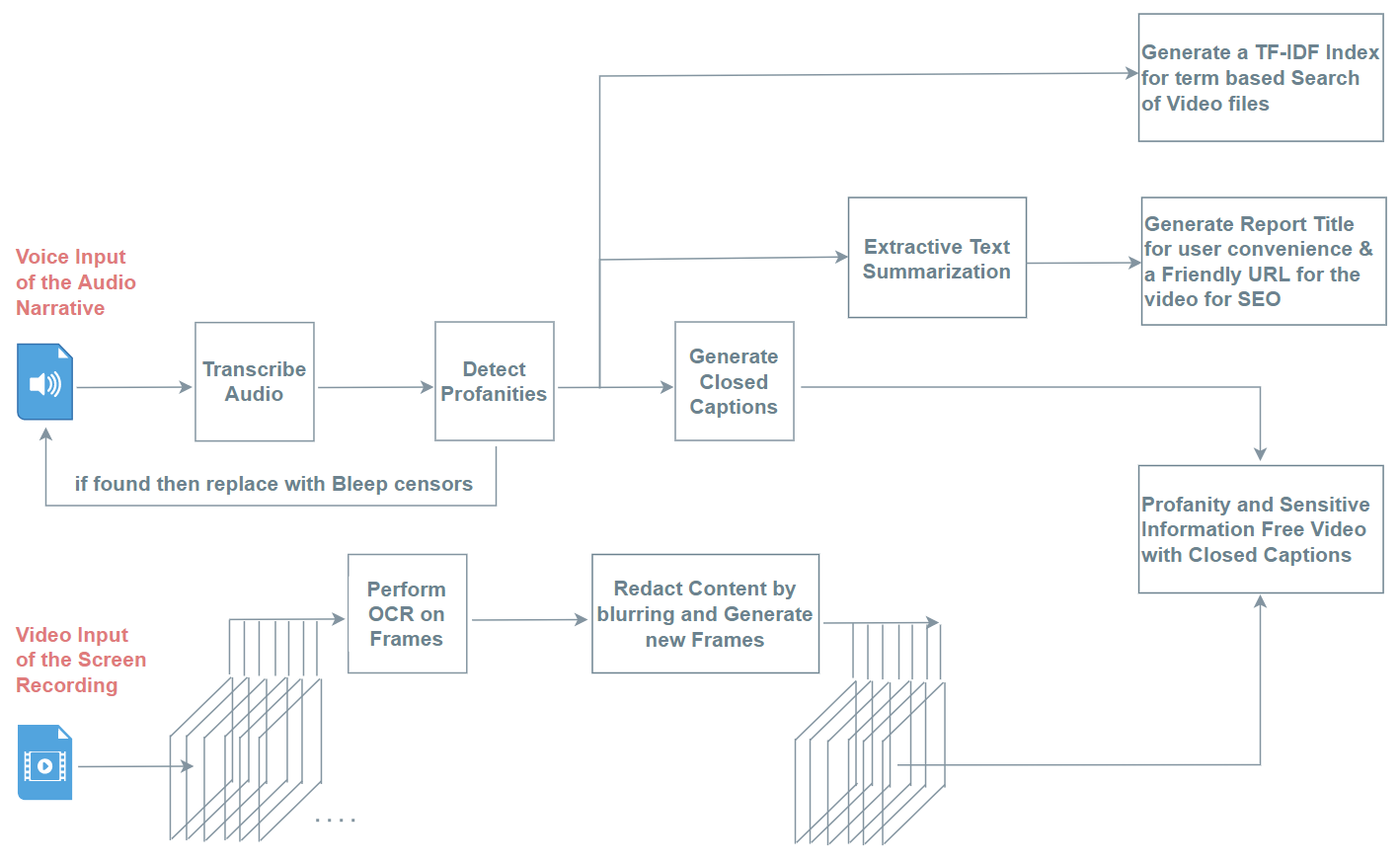
Details of the AI Pipeline The AI Pipeline described above takes inputs from a Bug Reporters Audio Narrative and Screen Recordings of User’s Actions and applies several processing and AI algorithms to get the outcomes laid out earlier. The Inputs and Outputs can be laid out more formally as –
Inputs- Audio input file (.wav format) produced from the WebRTC Server.
- Video Input file (.webm format compressed with VP8) from the Backend Server collecting the video streams passed through WebSocket connection.
These inputs are passed through several steps in the AI Pipeline as shown in the schematic diagram below to get the following outputs –
Outputs- 1. Profanity and Sensitive Information free Video with Closed Captions.
- 2. A TF-IDF index generated from the Transcription text of the Audio.
- 3. A Friendly URL generated from the Transcription text for SEO and a Report (Video) Title for better User Experience.
A schematic diagram for the AI Pipeline for Audio and Video Inputs is shown in Fig. 3 below.
Techniques used in the AI Pipeline The AI Pipeline described above has several AI-based activities on the Audio input, but the most primary amongst them is that of Transcribing Audio. The transcription needs automatic speech recognition and conversion to text.
Automatic Speech Recognition The field of speech recognition generally has a handful of activities by itself and it has gone through an evolution of sorts starting from a combination of MFCC Deltas, Hidden Markov Model, and an N-gram based model to a Deep Neural Network based model that is a combination of CNN, RNN + CTC, and Neural Language Model to the more recent Self-Supervised wav2vec models from Facebook Research.
A through analysis of the wav2vec 2.0 Research Paper is in the Automatic Speech Recognition link, hence skipped here. The earlier generation of approaches using Deep Learning technique had Speech frequencies converted to a spectrogram, that formed the basis of feature extraction. A Convolutional Neural Network extracted features and fed it to Recurrent Neural Network that handled Time-Series data along with a Connectionist Temporal Classification for sequencing, like Hidden Markov Model did in even older versions of the models. This was followed by Neural Language Model replacing the N-gram.
Profanity detection A pre-trained Transformer based model such as BERT (Bidirectional Encoder Representations from Transformers) shows good results in detecting offensive language. This is the state-of-the-art technique when it comes to Profanity detection at this stage along with a host of other NLP tasks. A Transformer is a Neural network that tracks relationships in sequential data like a set of words in a given sentence and thus makes sense or learns context and meaning.
Extractive Text Summarization Again, BERT provides a very good result for Extractive Text Summarization and takes in a maximum word length parameter that is very handy while generating a relatively smaller length summary such as that of a URL or a Title of a document.
Besides the audio-based input, the AI Pipeline also handles a Screen recording Video input and must redact the content by blurring out the sensitive data in textboxes of the input video frames. The first step to such an activity is to identify if there is a sensitive text in the frame and to do that an OCR must be performed on the frame.
Optical Character Recognition The OCR is performed using a combination of OpenCV and Tesseract libraries to get the Text from each of the video frames. After the Text is extracted, it is matched with a list of sensitive words to check if one or more of them are present in the extracted text from the video frame. If any of these words are found a Hough transform is used to get the Textbox edges and then a blurring filter is applied, and a new frame is created. At the end of this process a new completely redacted video file is generated.
So, with the help of the afore-mentioned AI techniques, a responsible Software Quality Assurance tool can be created. A tool that aims to serve the Enterprise by creating this novel type of Bug Report which has all the necessary information to fix a software defect (bug) quite easily.